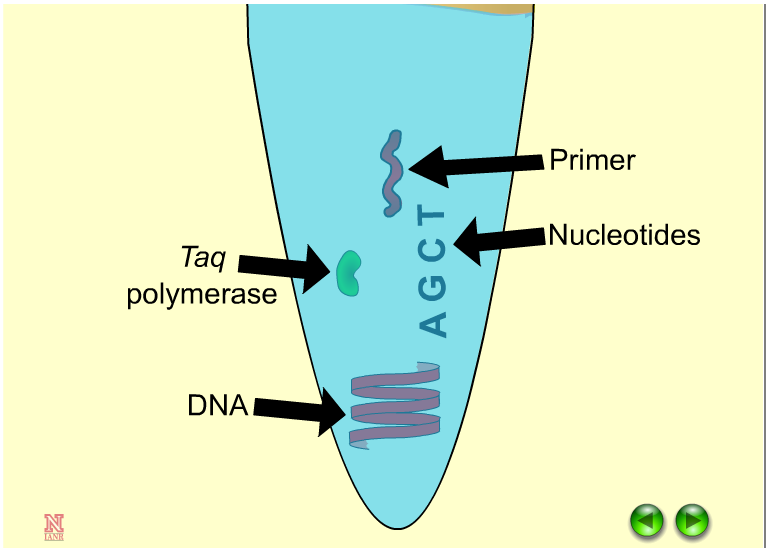
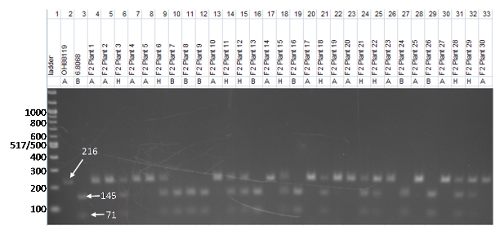
Regional information on topics important to barley is necessary to optimize production and is provided through organizations, universities and research and extension centers.

Photo credit: Patrick Hayes, BarleyWorld.org, Crop and Soil Science Department, Oregon State University
In the United States, barley is grown in 25 states, but the bulk of the production is in seven states. Each of these states hosts at least one checkoff organization, which collects money from producers to promote and support barley production, marketing, and research. As with most crops, certain information is critical for growers to optimize their chances to maximize production. Organizations, universities, and affiliated research and extension centers in each state provide such information on optimal variety selection, as well as state-specific information on marketing; economics; and prevalent diseases, insects, and weeds.
Idaho Barley Commission is a self-governed state checkoff organization that works for Idaho barley producers to improve production and profitability of barley in the state. This site provides information on management practices, market reports, newsbriefs, nutrition, and publications.
Idaho Grain Producers Association represents Idaho grain producers at county, state, and federal levels to ensure the viability and profitability of their farming operations. This site provides information on markets, research, and state agricultural agencies, and it links to the Idaho Grain Magazine.
University of Idaho Extension. Provides information on crops, fertilizers and soils, direct seeding and conservation tillage, and pests and pesticides. This site also has information on insect pollinators and irrigation.
USDA/ARS Aberdeen National Small Grains Collection. Maintains collections representing global diversity of small grains, including barley. The site houses the Barley Genetic Stock Collection, which contains over 2,000 germplasm lines of diverse geographic origin.
The Minnesota Barley Research and Promotion Council is a state checkoff organization that works with Small Grains.org to support barley research and interests. The Small Grains site provides information on markets, policy, and production issues.
University of Minnesota Agricultural Experiment Station is responsible for up-to-date research information, showcasing yearly evaluations of yield, agronomic, and disease characteristics of multiple barley varieties in Minnesota.
Montana Wheat and Barley Committee is a Montana Department of Agriculture organization, funded and directed by producers through a checkoff program. Their goal is to protect the interests and viability of wheat and barley production in Montana. The site provides information on rail rates, weather, and news.
Montana Grain Growers Association is an association of grain producers that works to represent Montana grain growers through legislation efforts that affect farming. This site contains information on policy, research, news, and local events.
Montana State University Agricultural Research Centers are located throughout the state. This site provides localized information on research related to varieties, pest and disease control, and other barley production issues.
North Dakota Barley Council is a producer-run organization, supported by checkoff funds, that provides information on barley utilization, research, marketing, and legislation. North Dakota is the top-ranked barley production state in the U.S.
North Dakota Grain Growers Association provides marketing and weather information, as well as the Gleaning newsletter, which contains information on grain yields, market prices, and other regional information of interest to growers.
NDSU Agricultural Experiment Station provides information on variety trial results, insect pest reports and management recommendations, and information on weeds and weed resistance.
North Dakota Irrigation Association has a publication that provides recommendations for irrigated malt barley production. Posted with permission by North Dakota Irrigation Association.
Institute of Barley and Malt Sciences. This institute provides information on the 2008, 2009, and 2010 American Malting Barley Association (AMBA) list of approved malting barley varieties. A detailed malting production calendar is also available.
Washington Grain Alliance provides funded research project summaries, as well as marketing and general crop information.
Washington State University Cereal Variety Testing Program provides weather data, variety brochures, and monthly rust updates.
Maryland Grain Producers provides information on their checkoff grant program, general information on biofuels, and a speakers bureau established to raise awareness of agriculture.
University of Maryland’s Research and Extension Centers provide information on the use hulless barley for ethanol production and screening barley cultivars for ethanol production.
Barley World, operated out of Oregon State University, offers an image gallery, information on barley food and straw and winter malting/food/forage barley breeding.
Oregon Wheat Growers League provides up-to-date local weather conditions.
Oregon State University, Crop and Soil Science Department barley page. This site contains information on varieties, diseases, nutrient management, and weeds.
USDA-ARS-Cereal Crops Research Unit, located in Madison, WI. This site contains information about research programs and projects, barley quality analysis, and news.
National Barley Growers Association is a national barley advocacy organization that works to ensure that US barley producers’ concerns are heard both nationally and internationally. This organization works closely with federal policymakers, congressional offices, and regulatory agencies to ensure barley producers’ concerns are addressed.
National Barley Improvement Committee is a national coalition representing barley producers, researchers, and end-users that works to address and discuss important national and regional barley research issues, and to ensure adequate funding for these areas. This site provides data on the economic significance of barley.
U.S. Grains Council is a private, nonprofit organization that works to build export markets for barley, corn, and sorghum. This site provides a database of grain suppliers and the Grains News newsletter.
U.S. Wheat and Barley Scab Initiative is an USDA–ARS-funded research project with the aim of developing effective control measures against Fusarium head blight (scab); the website provides links to a FHB risk assessment tool, Regional FHB Management Sites, and grain sampling for DON analysis.
Barley in China
. Article regarding the the Chinese barley industry and the cultural and national economic changes in recent years. Hertsgaard, K. and Wang, X. 2011. Barley in China. Institute of Barley and Malt Sciences Newsletter, Issue 14, April 2011.
Funding Statement
Development of this page was supported in part by the National Institute of Food and Agriculture (NIFA) Barley Coordinated Agricultural Project, agreement 2009-85606-05701, administered by the University of Minnesota. Any opinions, findings, conclusions, or recommendations expressed in this publication are those of the author(s) and do not necessarily reflect the view of the United States Department of Agriculture.
PBGworks 938